
Teil 6 der BLOGSERIE:

„Data-Driven Marketing: Wie die kundenzentrierte Ansprache in Zukunft gelingt.“
Erscheinungsintervall: alle 6 Wochen
Lesedauer: 7 Min.
Lesen Sie hier die anderen Beiträge dieser Blogserie:
- Teil 1 „Herausforderung Customer Centricity: Wie etabliert ist Datenanalyse im E-Commerce?“
- Teil 2 „Mit Open Source Tools individuelle Reports erstellen“
- Teil 3 „Langfristige Kundenbindung mit Hilfe von „Advanced Analytics“
- Teil 4 „Wann bleiben die Kunden vor der Tür stehen? – Predictive Analytics mit Maschinellem Lernen“
- Teil 5 „Gezielte Kundenansprache dank KI“
- Teil 7 „Data-Driven Marketing: Wie kundenzentrierte Ansprache in Zukunft gelingt in 3 Schritten“
In den vorangehenden Beiträgen haben wir Analytics und Maschinelles Lernen eingesetzt, um das Verhalten der Kunden im Google Merchandise Store zu verstehen. Mit den dadurch gewonnenen Erkenntnissen können wir Marketing-Maßnahmen besser planen und zielgerichteter agieren. In diesem Beitrag beschäftigen wir uns nun damit, wie wir unterschiedliche Kunden mit speziellen, automatisch zugeschnittenen Angeboten besser abholen können. Dafür erweitern wir unsere einfache Advanced Analytics Architektur um ein weiteres Element.
Aus dem aufgehäuften Wissen lernen
Mit Hilfe von Clustering-Verfahren konnten wir verschiedene Kundenarten ausmachen, die sich in ihrem Verhalten unterscheiden. Viele Kunden sind sogenannte „Eintagskunden“, die einmalig eine Hand voll Produkte bestellen, jedoch selten zurückkehren. Auf der anderen Seite steht ein viel kleinerer Kreis von Kunden, die wiederkehrend größere bis sehr große Bestellungen aufgeben, sich auf bestimmte Produktkategorien spezialisieren und „Power User“ darstellen.
Es stellt sich die Frage, wie wir die Schar der „Eintagskunden“ in einem Data-driven Ansatz besser abholen können, obwohl es keine länger bestehende Kundenbeziehung gibt und daher eine entsprechende Datenhistorie fehlt.
Wir könnten die Web Analytics Daten dafür nutzen, die Customer Journey und/ oder die Suche zu optimieren, und uns darauf verlassen, dass der Shop insgesamt besser funktioniert. Um auf den einzelnen Kunden einzugehen, erscheint aber ein anderer Ansatz vielversprechender: Die Gesamthistorie aller vergangenen Käufe zu betrachten, um Muster in den Vorlieben aller Kunden zu erkennen. Zeigt ein Kunde Interesse an einem Produkt, könnten wir dieses Wissen verwenden und mit passenden Angeboten reagieren.
Das ist die Idee hinter intelligenten Recommendations: Die Intelligenz der Masse zu nutzen, um dem potentiellen Kunden Produktempfehlungen zu präsentieren, die ihn wahrscheinlich ansprechen und besser durch das Sortiment führen. Im Gegensatz dazu sind statische Recommendations Pauschalangebote, die unspezifisch allen Besuchern präsentiert werden.
Amazon verdankt seinen Aufstieg zu einem Großteil der Entwicklung von guten Verfahren für intelligente Recommendations. Heutzutage begegnen uns Recommender-Systeme an diversen Stellen, wie Reiseportalen oder Audio- und Video-Streamingdienste.
Das Grundprinzip für intelligente Recommendations
Im Gegensatz zu Ratings oder Bewertungen eignen sich getätigte Kaufaktionen von Kunden sehr gut dafür, Voraussagen über weitere Käufe zu machen. Auf dieser Idee basiert eine Reihe von Algorithmen, die unter der Rubrik „Collaborative Filtering“ zusammengefasst werden. Das Prinzip ist immer ähnlich: Ausgehend von der Kaufhistorie aller einzelnen Kunden, der „Kunde-Produkte-Matrix“, wird eine sogenannte „Produkt-Produkt-Matrix“ aufgebaut, anhand der sich ablesen lässt, welche Produkte zusammen gekauft werden („Kookkurrenzen“). Die Kunst beim spezifischen Algorithmus besteht darin, aus der Produkt-Produkt-Matrix statistisch signifikante Zusammenhänge zwischen Kookkurrenzen zu extrahieren und in ein sog. Recommendations-Modell zu gießen (s. Abbildung 1.) Mit dem Modell kann man dann für ein Produkt oder eine Menge von Produkten passende Produkt-Empfehlungen generieren.
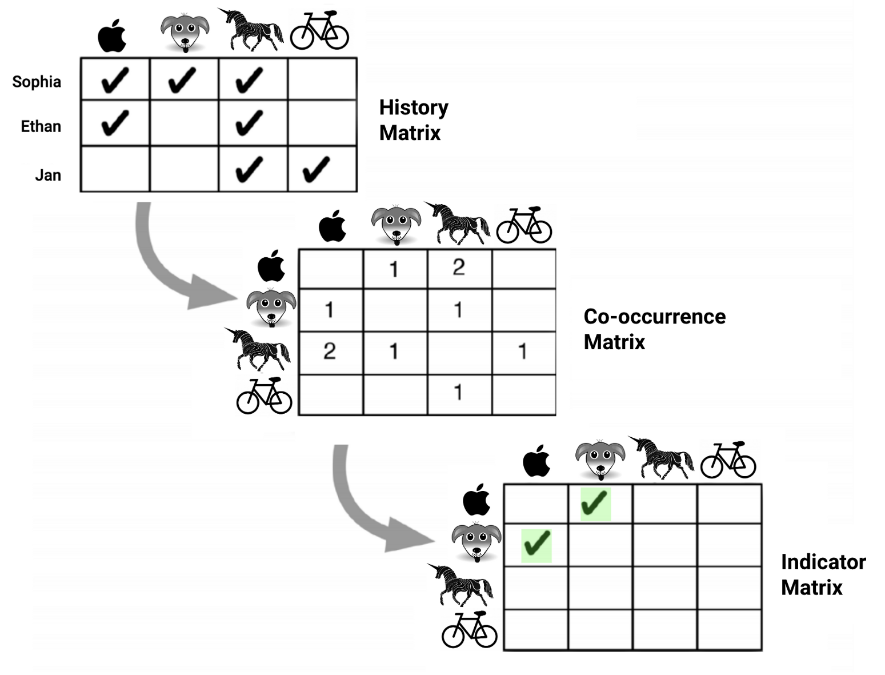
Ein Beispiel: Spaghetti, Tomatensoße und Wein werden oft zusammen gekauft. Wenn alle unsere Kunden jedoch unabhängig von ihrer Vorliebe für eine bestimmte Küche generell gerne Wein trinken, wäre Wein keine besonders gute Empfehlung zu einem Produkt wie Spaghetti. Tomatensoße vermutlich schon. Dafür muss aber der Zusammenhang zwischen Spaghetti und Tomatensoße statistisch feststehen.
Der „Alternating least squares (ALS)“-Algorithmus, der auf algebraischen Methoden basiert, ist sicherlich der bekannteste Ansatz beim Collaborative Filtering. Die Palette reicht jedoch bis zum Deep Learning; dabei kommen beispielsweise „Siamese Neural Networks“ zum Einsatz, um Produkte anhand von einer Vielzahl von reichhaltigen Merkmalen zu beschreiben und miteinander zu vergleichen.
Die Herausforderungen sind unabhängig des Algorithmus immer ähnlich:
- Man braucht eine gute Datengrundlage, um nützliche Zusammenhänge zu erkennen; idealerweise in Form einer langen Kaufhistorie.
- Bis eine solide Kaufhistorie zur Verfügung steht, muss das sogenannte Cold-Start Problem gelöst werden; d.h. es muss eine alternative Strategie entwickelt werden, um Recommendations anzubieten, die auf weniger zuverlässigen Daten wie PageViews, Reviews, usw. aufbaut.
- Man muss dafür sorgen, dass Empfehlungen mit der Zeit nicht langweilig werden und genügend Variation anbieten, um sogenannte Filterblasen zu vermeiden.
Die Verwandtschaft von Suche und Recommendations ausnutzen
Zwischen Suche und Recommendations besteht eine gewisse Verwandtschaft. Zum einen kann ein Suchproblem als Empfehlungsproblem aufgefasst und gelöst werden. Bei der Berechnung der besten Ergebnisse zu einer Suchanfrage fließt zum Beispiel bei Google ein, wie oft Seiten von anderen Seiten in Form von Verlinkungen „empfohlen“ werden. Daher sind die eingesetzten mathematischen Methoden in beiden Fällen oft sehr ähnlich.
Zum anderen sind Suchvorgänge neben den Käufen ein wichtiger Indikator für die Interessen des Shop-Besuchers. Was ist naheliegender, als Empfehlungen zu präsentieren, die zu seinen Interessen passen? Kein Wunder also, dass eine einfache Recommendations-Engine sich direkt auf derselben Suchmaschine implementieren lässt, mit der wir unseren Shop betreiben.
Für einen praktischen Test auf Basis der Google Analytics Daten setzen wir hierfür Elasticsearch ein. Damit erweitern wir die einfache Analytics Infrastruktur, mit der wir in unserer Serie bisher gearbeitet haben, um eine weitere Komponente, die eigene Analyse- und Visualisierungs-Möglichkeiten mitbringt.
Eine Recommendations-Engine für den Start
In einer ersten Ausbaustufe unserer Recommendations-Engine setzen wir Spark als ETL-Framework ein. Wir extrahieren aus den Google Analytics Daten die Transaktionsdaten zu unserem Shop, und transformieren sie anschließend in eine Customer-Item Matrix, die sich dann als Index in Elasticsearch laden lässt, s. Abbildung 2.
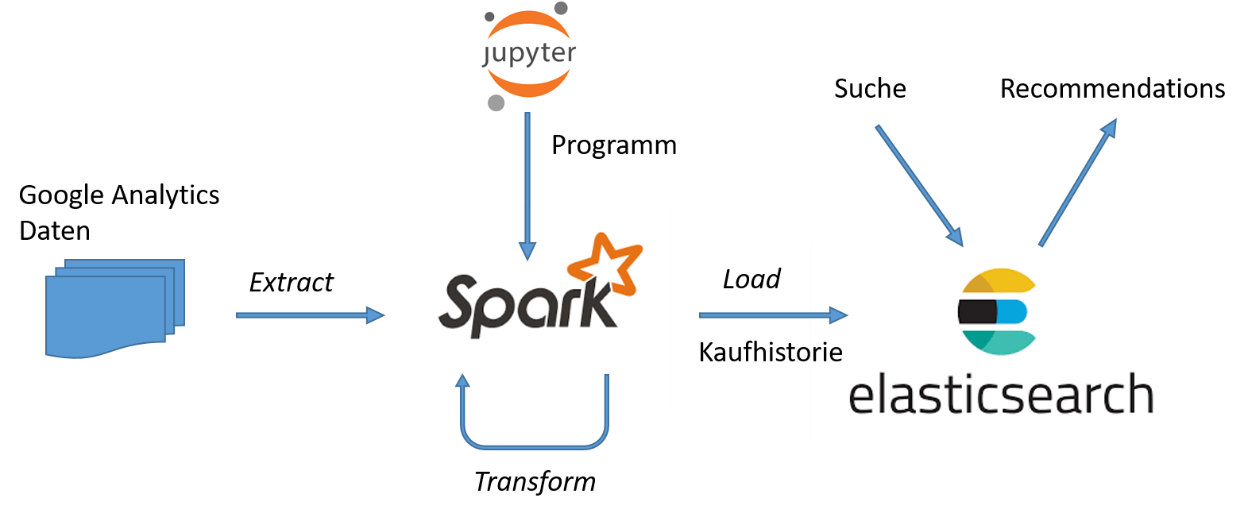
Die Extraktion und Transformation der Daten mit Spark erfolgt ähnlich wie bei den Vorbereitungen für das Clustering von Kunden. Ein Jupyter Notebook zur Berechnung der Customer-Item Matrix aus den GA-Daten kann hier runtergeladen werden:
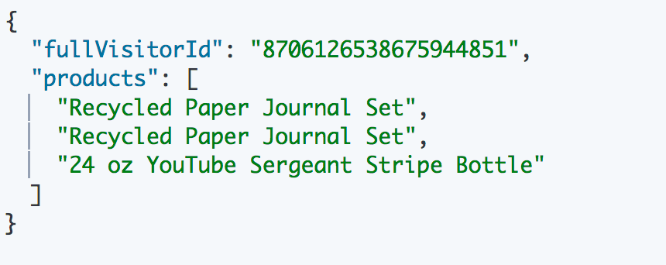
Die Customer-Item Matrix geben wir als Menge von JSON-Dokumenten heraus. Für einen einzelnen Kunden sieht der Eintrag dann so aus:
Die einzelnen Dokumente lassen sich anschließend mit Hilfe der Elasticsearch Spark API in einen Elasticsearch-Index laden.
Dadurch stehen uns die Statistik-Fähigkeiten von Elasticsearch für die Berechnung von Recommendations zu Verfügung. In diesem Fall nutzen wir die sog. Aggregationsfunktionen, sodass wir „on-the-fly“ für ein bestimmtes Produkt die statistisch signifikanten Kookkurrenzen ermitteln.
Zunächst ermitteln wir mit Hilfe der „terms“ Aggregations-Funktion, wie viele Kunden jedes einzelne Produkt gekauft haben. So erhalten wir eine Liste der am häufigsten gekauften Produkte. Dazu dient die Anfrage:

Als Ergebnis erhalten wir:
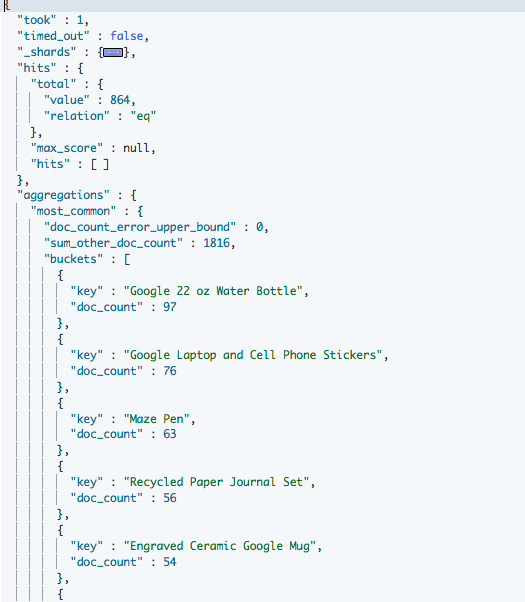
Von den 864 Kunden im Index haben 54 ein „Engraved Ceramic Google Mug“ gekauft. Welche anderen Produkte haben diese Kunden außerdem noch gekauft? Um das zu wissen, brauchen wir die Kunden nur durch eine entsprechende Suche einzugrenzen und die „terms“-Funktion nochmal zu bemühen:

In diesem Fall sieht das Ergebnis so aus:

Dadurch haben wir dynamisch einen Teil der Produkt-Produkt-Matrix. Wir erfahren, dass von den 54 Kunden, die die Google Tasse gekauft haben, sich 11 auch für Stickers entschieden haben („Google Laptop and Cell Phone Stickers“). Sind also Google Stickers die beste Empfehlung zu einer Google Tasse? In der Liste der am häufigsten gekauften Produkte sehen wir, dass die Google Stickers immerhin noch vor der Google Tasse stehen; sie scheinen also allgemein beliebt zu sein und nicht besonders mit dem Kauf einer Tasse zu korrelieren. Wir hätten also zusammenhängende Produkte besser nicht nach der Häufigkeit, sondern nach der Stärke der Korrelation sortiert. Das erreichen wir durch den Einsatz der „significant-terms“-Funktion:

Dadurch ändert sich die Reihenfolge in den Ergebnissen:

Siehe da: Ein „Red Shine 15 oz Mug“ hängt statistisch gesehen stärker mit der Google Tasse zusammen als die Sticker, die einen viel niedrigeren Score als der „Mug“ aufweisen. Die Grundidee für die Berechnung des Score ist folgende: Man vergleicht den Anteil von einem Element (hier z.B. dem Mug) in der Gesamtmenge, dem „Hintergrund“, mit dem Anteil desselben Elements in der reduzierten Menge oder „Vordergrund“, die das Element enthält, zu dem man die Korrelation berechnen möchte (hier die Google Tasse). Der Score ist ein Maß dafür, wie der Anteil eines Elements steigt, wenn man vom Hinter- zum Vordergrund übergeht. Der „Mug“ kommt im Hintergrund eher selten vor („bg_count“ 28 von 864), sein Anteil im Vordergrund ist viel größer („doc_count“ 10 von 54). Die Google Tasse ist im Hintergrund mehr als zweimal häufiger (bg_count = 76 von 864), weswegen der Anteil im Vordergrund vergleichsweise nicht so stark steigt („doc_count“ 10 von 54). Die genaue Formel wird durch den JLH Score gegeben. In Elasticsearch kann man für die Berechnung von „significant-terms“ auch auf andere statistische Assoziationsmaße wie Chi-Square, Mutual Information, usw. zurückgreifen.
Damit haben wir eine erste Version für ein Recommender-System implementiert, die auf Suchanfragen reagieren kann und sich leicht verbessern lässt. Statt alle Käufe gleichwertig zu behandeln, können wir beispielsweise weitere Metriken wie Page Views oder Ratings in die Berechnung einfließen lassen, oder Kundenmerkmale bei Filtern berücksichtigen.
Auch wenn die Ergebnisse noch nicht ganze perfekt sind, können wir mit diesen einfachen Mitteln zumindest das Cold-Start Problem entschärfen, wenn wie hier die Kaufhistorie noch nicht besonders groß ist.
Mit den Daten wachsen und immer besser werden
Durch die Erweiterung unserer Infrastruktur um Elasticsearch entstehen mehrere Möglichkeiten, von einer wachsenden Menge an Daten zur Kaufhistorie und Kundeverhalten zu profitieren und unser Recommender-System anzupassen.
Eine weitere Ausbaustufe ist in Abbildung 3 skizziert. Spark dient nicht nur als ETL-Tool, sondern wird auch eingesetzt, um mit Hilfe des vorhandenen ALS-Algorithmus ein Recommendations-Modell zu berechnen. Elasticsearch dient als Backend für den Shop und enthält den Produktkatalog, der mit den Ergebnissen der Berechnung angereichert wird.

Mit der Zeit und mit hoffentlich wachsender Käuferzahl möchte man wahrscheinlich nicht nur mit einer statischen Historie als Grundlage für die Recommendations arbeiten, sondern auf Änderungen im Kaufverhalten und kurzfristige Interessen dynamisch reagieren.
Das bedeutet, dass z.B. die Folge der Interaktionen eines Kunden in einem Zeitfenster betrachtet werden oder die Kunde-Produkt-Matrix regelmäßig aktualisiert werden soll. Im Grunde möchte man möglichst viele Kundensignale berücksichtigen, um noch präziser auf den Einzelnen eingehen zu können.
Diese Signale stellen fortlaufende zeitliche Events dar, die die Infrastruktur verarbeiten muss, um sie nutzen zu können bspw. die Kaufhistorie aktuell zu halten. In unserer Architektur mit Elasticsearch und Spark haben wir gleich diverse Optionen, dies zu tun, u.a.:
- Die Events lassen sich in Elasticsearch in einem eigenen Index fortlaufend erfassen. Dieser Index wird dann in regelmäßigen Zeitabständen mit Hilfe von sog. Transforms, einem eigenen Elasticsearch-Mechanismus, abgefragt und in den Kaufhistorie-Index umgewandelt.
- Alternativ können mit der Spark Streaming API ebenfalls Events konsumiert werden. Aus diesen werden dann innerhalb von Spark Änderungen an der Kaufhistorie berechnet und an Elasticsearch übermittelt.
Ausblick
Mit intelligenten Recommendations können wir dynamisch auf Interessen des Einzelnen reagieren, selbst wenn wir sie oder ihn noch nicht kennen und „persönlich“ ansprechen können. Damit unterstützen wir unsere Kunden und lassen den Umsatz steigen. Voraussetzung ist, dass wir aus der Vergangenheit lernen und die Signale nutzen, die uns zur Verfügung stehen, allen voran konkrete Käufe.
Mit der Erweiterung unserer Analytics-Plattform um Elasticsearch sind wir in allen Ausbaustufen der Realisierung von Recommendations besten aufgestellt.
In nächsten Beitrag nutzen wir Kibana, das wie Elasticsearch ein Teil des Elastic Stack ist, um mit geeigneten Visualisierungen unsere Marketing-Aktivitäten zu steuern.Elasticsearch and Kibana are trademarks of Elasticsearch BV, registered in the U.S. and in other countries.